喧嚣背后,国产gpu距离“平替”英伟达还有多远?-尊龙凯时最新

2024年上海的7月是一个沉闷的雨季,但对国产ai 行业来说,却迎来了堪比摇滚乐集会的waic(世界人工智能大会)。
会上,阿里的通义千问、智谱ai基座大模型、商汤科技的vimi可控人物视频生成大模型等“镇馆之宝”通过展示强大的agi能力起到了十足的吸睛效果。但除了在观众面前展示ai前端效果的大模型,国产ai的基座:国产算力,也进行了一次集中的亮相,包括壁仞科技、摩尔线程、燧原科技、国科微、无问芯穹、天数智芯等数量繁多的国产ai芯片公司密集的展示了自己的产品线,这些产品线涵盖了训练到推理、包含了端侧和云侧、既有通用gpu、又配齐了各类场景的ai加速卡,可以说是要给英伟达一点:“小小的中国震撼”。
当观众游走在国产算力馆,观摩齐全的产品线和亮眼的单卡性能,直观的感受就是这个行业“繁花锦簇”、“生机勃勃”,与大洋彼岸的相比并不逊色多少。但是每天打开新闻,看到对岸不断收紧的制裁绳索,似乎又很难支持这个“国产ai芯片”处于行业爆发期的结论,那么今天我们必须直面的问题是:眼前的“繁华”,是否有坚实的基础?
01
国产大模型的蓬勃发展遇上国外芯片制裁,如同切下一块纯纳掷进水池,瞬间就引爆了国产gpu市场。
如果翻看中国芯片自主化的紧迫历史,从早期龙芯、飞腾冲击wintel 联盟,到麒麟芯片的松山湖战役,行业的注意力都是放在设备的核心处理器上,因此cpu类型的核心无论是在政府还是投资人角度来看,都是更为核心的突破点,获得了政府的信创订单和大量资金投入,2023年底的麒麟归来,更是国产芯片对于外部封锁的一记有力回击。
但在处理器战线取得突破的同时,gpu作为一个曾经的侧翼战场,却忽然切换成了主战场。随着ai 大模型在2023年的横空出世,作为大模型发动机的gpu需求猛烈增长,英伟达2023年收入增长125%,2024年一季报更是增长262%,以一种一骑绝尘的速度降其他芯片巨头甩在身后。
作为对比,曾经计算机时代的芯片王者英特尔和移动互联网时代王者高通市值相加仅仅3000多亿美金,不到英伟达的1/8,新王,被喷涌而出的ai训练需求簇拥上了王位。
但令人尴尬的是,这场ai大潮,美国人并不计划给中国留一张头等舱的船票。在美国政府的要求下,英伟达、amd只能对a100和h100等高端型号的gpu进行断供,转而向国内提供h20等“中国特供版”产品。而“特供版本”比起“正版”来说,颇有些鸡肋之感,在一些科技媒体的测评中,h20的综合算力仅相当于h100的20%,且由于增加了其他硬件配置,使算力成本显著提高。
在这种半卡脖子的情况下,国产大模型与国产ai芯片的协作,自然成了应有之意。此外,中国强大的算力中心需求,也给了国产gpu一个庞大的市场。要知道,截至2023年底,我国数据中心机架总规模突破810万架,算力总规模达到惊人的230eflops,是仅次于美国的算力大国。
因此我们也能看到一个个非常切实的国产芯片落地数据中心的案例:
壁仞科技,成为了中国电信的算力尊龙凯时最新的合作伙伴,同时搭载壁砺系列通用gpu算力产品的中国移动智算中心(呼和浩特)近日成功上线运营。这家智算中心属于全国型n节点万卡训练场,单体算力达6.7eflops(fp16),也验证了壁仞宣称的产品可以用于千卡集群建设方案,并可扩展至万卡规模的互联技术的落地能力。
摩尔线程,也针对自己的ai旗舰产品夸娥(kuae),推出了一整套尊龙ag旗舰厅官网的解决方案,其中包括夸娥集群管理平台(kuae platform)以及夸娥大模型服务平台(kuae modelstudio)。这针对的就是万卡数据中心在如此多算力卡高速互联的同时,如何保持稳定运行以及高效的计算资源调配问题,同时也一口气签约了青海零碳产业园万卡集群项目、青海高原夸娥万卡集群项目、广西东盟万卡集群项目。
除了云侧,端侧上ai大模型需求的匹配能力也是不少ai芯片公司的切入点。
比如燧原科技就和智谱ai合作推出了大模型编程助手一体机,基于云燧i20推理加速卡,能为软件开发企业提供一系列aigc功能(如代码生成、代码翻译、代码注释、代码补全、智能问答)。沐曦科技则利用自己的曦思n100,与眸瑞科技联合发布了首个ai模型“贴图超分”技术。百度旗下的昆仑芯更不用说,更是针对文心一言进行了深度的优化。
另一点不可忽视的是,国内的资本市场也给gpu行业发展带来了极大的支撑,比如2023年底,摩尔线程和壁仞科技都完成单轮融资超过20亿的壮举,沐曦科技也轻松单轮融资10亿,这在2023年已经跌入冰点的资本市场可谓是奇迹。
可以说,国产算力中心和国产大模型,正在从硬件匹配和软件生态两个方向支援国产,这一点是国产gpu玩家敢于应对国际巨头的底气所在。但,一切都这么顺理成章吗?
02
在新闻稿的喧嚣背面,算力中心和大模型公司都有点“口嫌体正”地疯抢英伟达gpu。仅仅在2023年,英伟达中国的收入就高达806亿人民币,而同期国产gpu的成绩可谓寥寥。
a股的gpu第一股:景嘉微,在2024年第一季度仅仅实现了1.08亿元营收,虽然同比增长66.27%,但其实还不到2022年的1/3。
在新闻报道和券商研报里,长期算力吊打英伟达的算力第一股寒武纪,一季度收入仅仅2500万,同比下降65%。
从人工智能应用侧转型开展人工智能芯片的云天励飞,2023年全年的芯片收入仅2400万。
一级市场的芯片公司收入则更加不透明,如自称是国内首家真正量产的通用gpu企业的天智数芯,曾披露自己2022年全年收入是2.5亿、一些估值已经奔着数十亿乃至百亿的公司,在每天发布合作和订单协议的背景下,实际落地交付的收入,不过千万级别。
可以说,热闹之下,大部分“战略合作”、“战略签约”,更像是一种示范而非实质落地。
不得不承认一个现实,单纯的拿着纸面参数去pk英伟达意义并不大,千亿参数大模型以及背后的万卡数据中心要能稳定持续高效的运行从来都不是一个单点维度的事,也从来不是可以短时间一蹴而就的事。
实际上,即使最简单大模型评测维度,也包含至少5个方面:
(1)单卡性能
(2)卡间互联
(3)集群利用率
(4)对大模型训练的支持
(5)对现有生态的兼容
对于各家国产gpu而言,也许可以单项有亮点,例如华为的单卡性能,未必弱于英伟达,沐曦科技的显卡,在兼容过往的显卡生态上表现也超于业界预期、百度的昆仑芯片在支持自家文心一言等大模型训练效率上算是优势显著,但做到五边形战士,只有英伟达,而其他人五边形缺上一个角,就难以落地。
比如公认的英伟达的护城河之一的cuda生态, 可以说离开cuda,大部分程序员都不知道如何在gpu的硬件平台上进行开发,其软件生态已经渗透到了ai、科研等领域的方方面面。百度曾经的首席科学家吴恩达就评价:cuda出现之前,全球能用gpu编程的可能不超过100人,而目前全球的cuda开发者已经达到几百万。
这都归功于英伟达早在2006年就大力支持cuda系统在ai领域的开发与推广。当时英伟达每年投入5亿美元的研发经费,对cuda进行不断更新与维护,而同期营业额只有区区30亿美元。与其同时,英伟达还让当时美国大学及科研机构免费使用cuda系统,使cuda系统迅速在ai以及通用计算领域开花结果。
在支持大模型领域,英伟达更是早早的走在了所有人前列。少有人知道的是,英伟达在2016年斥巨资打造了全球第一台ai超算dgx-1后,首先就将它捐给了还处于萌芽状态的open ai,也早早的与大模型生态结下了深厚渊源,在大算力芯片互联领域,nvlink 对于竞争对手也是一骑绝尘,连同为美国显卡巨头的amd也不得不望洋兴叹。一个常识是,gpu的算力不会简单叠加,单颗数据刷单再高,如果没有好的连接技术,1 1开始就小于2, 10 10能不能到15都需要打一个问号。
在其他厂家还在局限于传统的pcle时,英伟达也已进行了超过10年的布局。早在2014年,英伟达就发布了nvlink 1.0并在p100 gpu芯片之间实现,已经是当时pcle 3的5倍传输速度;在2020年,英伟达完成了对mellanox的收购 ,又获取了infiniband、ethernet、smartnic、dpu及linkx互联的能力,可谓是如虎添翼;到如今, nvlink已经可以实现每个gpu之间高达每秒600gb的频宽,比pcie 4.0高出十倍。
因此,在一些评论家眼中,英伟达是一条“三头巨龙”,强大的gpu算力、丰富的软件生态、高速的宽度连接让其构建出一个攻守兼备、难以突破的产品防线。一旦试图绕开它的生态,就可能面临购买了万卡只能跑出千卡算力数据堰塞的窘境,有可能遭遇编程开发到一半,没有合适的应用开发工具的难题。这种损耗对投资巨大的ai 算力中心无疑是不可接受的,对于工程化工作极为庞大的、优化工作繁重的大模型开发者也是不可承受之痛。
而更为显著的差距在于,英伟达目前依然在为客户降本的道路上狂奔不止。
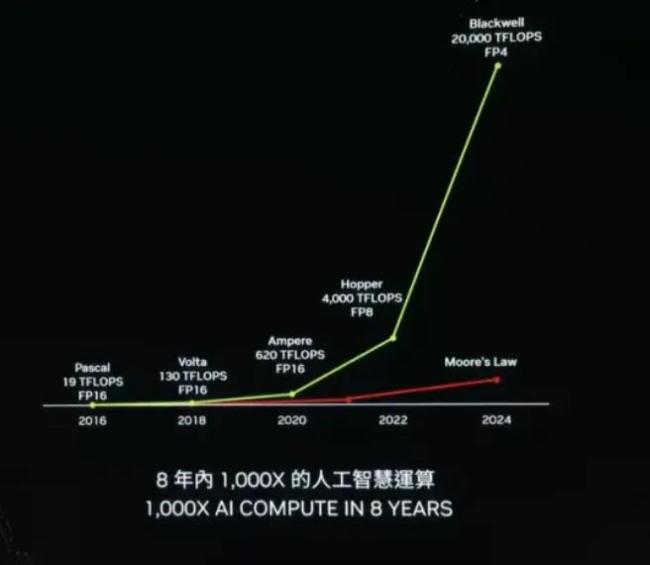
黄仁勋有句对客户对名言:“买的越多,省的越多。”人称黄氏数学。切换到目前ai大模型角度,就是如何在硬件层面实现大模型训练和生成token的降本。在今年6月,基于blackwell架构的gb100芯片,相比于h100,将成本和能源消耗降至1/25,在参数为1750亿的gpt-3llm基准测试中,gb200的性能达到了h100的7倍,而训练速度则达到了h100的4倍,硬生生的让7万美金一枚的芯片卖出了性价比。
可以说,让把一个千亿参数大模型和万卡数据中心建立在一个软件生态和通信互联都没有经历时间和案例验证的硬件上,就如同不勘探地基下面的地形地貌就一意孤行的搭建摩天大楼。而直接全面用国产gpu支撑国产大模型的token生成,也会把国产大模型公司的成本拉到不可承受之重。
因此雷声大,落地少,也就成了业界的一种无奈之举。
03
“速胜论”不可取,我们并不是就要滑向“速败论”。即使强大如斯,英伟达并不是能够取得每一场战役的胜利。
刚刚过去的 7 月 30 日,苹果公司发布了一篇研究论文,显示苹果使用了谷歌开发的 tpu 芯片人工智能系统“apple intelligence”中的 ai 模型 apple foundation model(简称 afm),据报道,苹果本次采购了超过1万片谷歌的tpuv5p 和tpuv4 芯片来平替英伟达gpu。
苹果和谷歌为何有这个底气开始局部替换英伟达?
一方面还是谷歌产品能够切合苹果本地模型不需要过多的参数训练,而谷歌的tpuv5e在性价比上具有显著优势,特别适合中小规模模型的训练,从而在这个细分市场让谷歌站住了脚跟。可以遇见的是,有了苹果这个成功案例,谷歌会不断的寻找新的侧翼战场来挑战英伟达,而不是直接与这个“六边形”战士对决。
另一方面,苹果作为全球消费电子一哥,采购个上万块tpu只是研发投入的九牛一毛,用来布局防卡脖子并不稀奇。
因此,耐心的先掌握终端市场,一方面利用庞大终端市场带来的巨大现金流保持研发投入,一方面不断的拿出有特殊需求的市场练兵和测试,才是面对先发优势过于明显的对手的优秀战术。
这方面,华为的麒麟芯片就是一个很好的经验案例。在中国的pc时代,曾经有过“贸工技”和“技工贸”的对立,最终单独冲击芯片的企业资金不足,单独冲击市场的企业后劲不足,也留下了柳传志与倪光南的遗憾终生。
但华为却没有把这两条路对立起来,该用高通的先用高通的,同时发挥中国在制造能力和软件迭代上的优势,不断的吃下市场,同时坚持对自家的芯片进行研发投入。当数千亿级别的市场和上千家适配的供应商都掌握在手时,自家的芯片也开始接棒,这种两条腿走路,最后实现双向奔赴的战略,才取得了切切实实的成功。
我们要意识到一点:一家成功的芯片公司,一定也是一家成功的企业,而一家成功的企业,必须要有源源不断的现金流。
我们也要明白,芯片不是那小小一块硅,而是无数软件玩家、硬件适配玩家、无数供应商,这需要的是有资金作为号召力。
因此,在目前情况下,我们当务之急并不是立刻拳打英伟达,而是可以利用市场环境和中国习惯,先建立起大模型的市场。不能被对岸的open ai、anthropic、llama甩开的出维度级别的差异,否则到那个时候,民众想支持国产大模型都困难了。而当国产大模型稳住13亿人的市场,乃至可以随着国产强大的消费电子硬件出海的时候,国产芯片也能有航母作为依托,而不得单独对抗海外巨头。
除此之外,在活下来的同时,国产芯片公司依然可以在时间维度上不断蚕食英伟达的护城河,软件生态不够,可以依托国内开发者和大厂不断补齐,连接能力不够可以与数据中心一道优化。实际上,这正是国产芯片公司正在做的。
目前,摩尔线程构建了musa生态来兼容cuda,提供几乎所有组件都有与cuda的对应关系。壁仞科技的birensupa平台、沐曦科技的mxmaca平台也都在通过兼容来削弱英伟达cuda的统治力,并且通过开源的形式吸引开发者加入来构建生态。
而在连接方面,由于nvlink的是英伟达独占,不仅国产gpu,连海外芯片厂商也开始试图联合冲击这条护城河。2024年3月,amd、博通、思科、google、惠普、英特尔、meta、微软八家巨头就一起宣布要为人工智能数据中心的网络制定新的互联技术ualink,行业共同解决链接问题也是大势所趋。
可以说,填平英伟达的护城河并不是国产芯片一家之力,英特尔ceo基辛格曾公开抨放话说cuda护城河又浅又窄,整个行业都想消灭它,英伟达过去数十年构建的生态固然可怕。但一家企业独占整个行业利润之时,时间就不在它一侧。
毫无疑问,虽然waic上,国产芯片的产品侧已然成势,但从点亮芯片到客户适配再到稳定运行、生态构建还有很长一条路需要走。如果我们光看到琳琅满目的介绍就认为已经“优势在我”,要去“教训教训”英伟达,乃至主动脱钩,无疑是鲁莽之举。但对国产芯片敬而远之、不给试错和验证机会也是歧路。
产业的发展的难处正是在于如何平衡外力和内力、平衡成本与创新、自主与全球,这是一条走起来需要时时审视策略、是走起来需要像独木桥上时刻保持平衡的策略,但也是走到对岸唯一可行的路。
推荐阅读
起底黄仁勋:为何中国没有英伟达?
英伟达(nvidia)这个生涩的单词源于拉丁语invidia,意为“嫉妒”。用这个“坏词”命名自家公司,的确体现了这家初创企业的反叛精神。
英伟达vs微软,谁能久坐全球市值第一“铁王座”?
英伟达与微软作为硬件软件领域的“巨头”,近期正围绕全球市值“一哥”的位置展开激烈的较量。
英伟达“过山车”式股价背后,ai芯片巨头地位并非不可动摇
在诸多乐观预测后,如今,华尔街对于 ai“泡沫化”担忧有所缓解,这促使投资者重新涌入科技领域,并且重振市场对 ai 芯片行业和英伟达的热情。
苹果“输给”英伟达,头显被迫走廉价路线?早已着手研究
苹果ceo库克此前也表示,vision pro是目前最先进的电子设备,它将是苹果的一个转折点,未来十年vision pro将会取代iphone的地位。
近期,美股科技继续狂飙,“芯片巨头”英伟达坐上“全球市值一哥”的王座。
随着人工智能技术的飞速发展,数据已成为ai训练不可或缺的资源。
东方甄选发力配送业务,然产品质疑还未解除。







